本文由清华大学 THUNLP 实验室联合上海科技大学、伊利诺伊大学厄巴纳-香槟分校、中国人民大学等多家机构研究者合作完成。
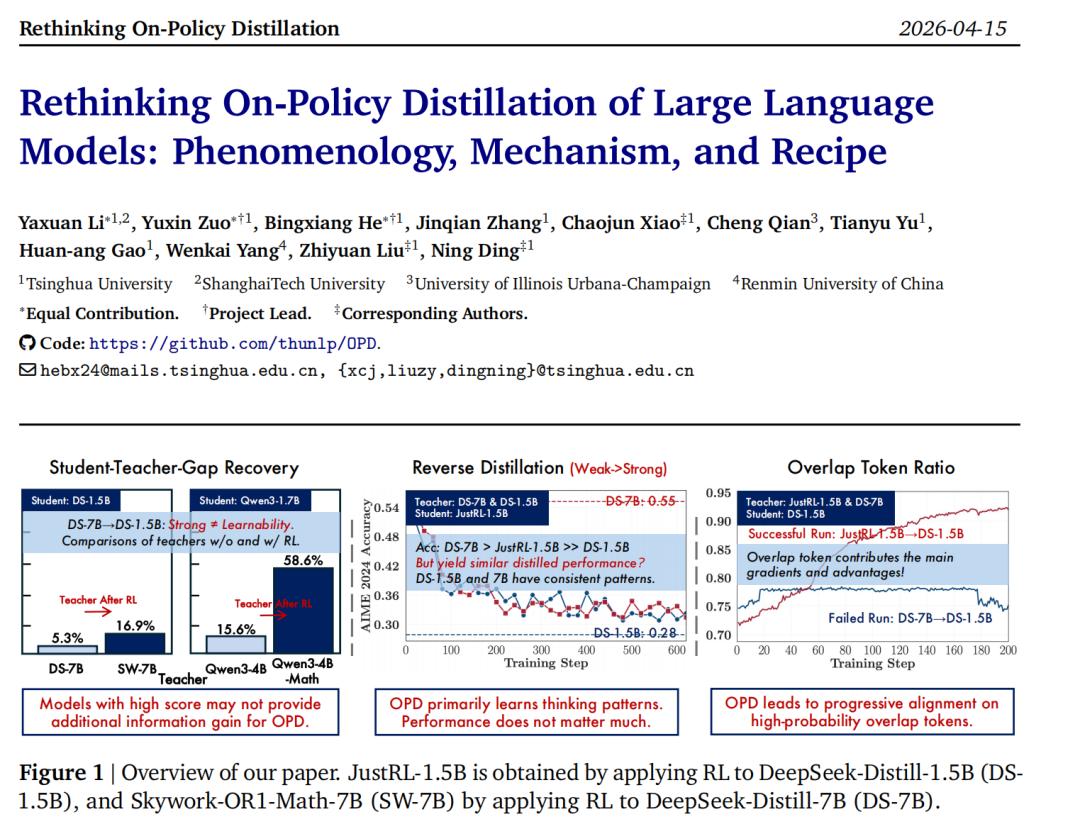
当下的大模型后训练(Post-training)pipeline 中,On-Policy Distillation(OPD)已经成为了明星技术。从 Qwen3、MiMo 到 GLM-5,业界纷纷采用 OPD 并报告了巨大的性能提升。相比于强化学习(RL)稀疏的结果奖励,OPD 提供了密集的 Token 级别监督信号,看起来就像是一顿「免费的午餐」。
但如果你亲手跑过 OPD,你可能会遇到一个反直觉现象:为什么我换了一个更强的 Teacher,Student 的性能反而毫无提升,甚至出现了倒退?
大模型时代的蒸馏,早就不是简单的「大力出奇迹」了。
清华大学团队最新的一项研究,系统性地解剖了 On-Policy 蒸馏的黑箱。这篇论文不仅揭示了决定蒸馏成败的两大先决条件,还深挖了 Token 级别的对齐机制,并给出了拯救失败蒸馏的实用配方。
发布时间:2026-05-14 15:00








 立即订购
立即订购 在线咨询
在线咨询 返回顶部
返回顶部